Video Generation as World Model
We introduce IRASim, a new world model trained with a diffusion transformer to capture complex environment dynamics. We incorporate a novel frame-level action-conditioning module within each transformer block, explicitly modeling and strengthening the alignment between each action and the corresponding frame. IRASim can generate high-fidelity videos to simulate fine-grained robot-object interactions, as shown in Fig. 1. To generate a long-horizon video that completes an entire task, IRASim can be rolled out in an autoregressive manner and maintain temporal consistency across each generated video clip.
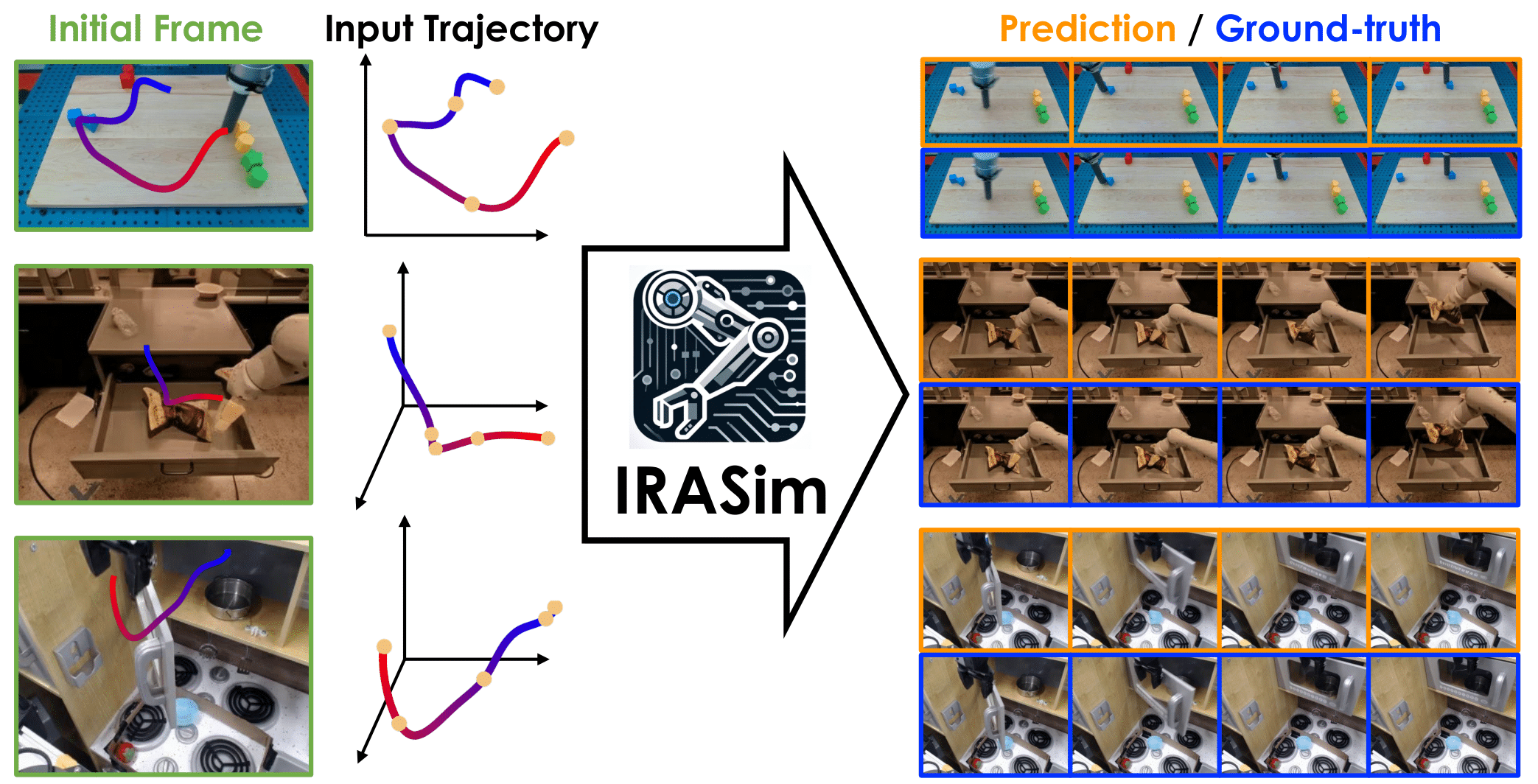
Figure 1: IRASim is a fine-grained world model for robot manipulation. It generates high-fidelity videos that simulate accurate robot-object interactions of a robot executes an action trajectory, given historical observation.
Short Trajectory Prediction
Uncurated qualitative results of short trajectories are shown below. Click the Click to View More button to display another random subset from 100 unpicked samples for each dataset. All samples are from the test set. Each video contains 16 frames with 4 fps. The video on the left is generated by IRASim, while the video on the right is the ground truth.
Long Trajectory Prediction
Uncurated qualitative results of long trajectories are shown below. Click the Click to View More button to display another random subset from 100 unpicked episodes for each dataset. Click the Click to View Very Long Videos button to display the six longest videos from the 100 unpicked episodes. Hover over on these longest videos to see their number of frames. All episodes are from the test set. The average number of frames of the 100 unpicked episodes are 47.04, 36.43, and 24.57 for RT-1, Bridge, and Language-Table, respectively. The video on the left is generated by IRASim; the video on the right is the ground truth. IRASim retains the powerful capability of generating visually realistic and accurate videos of long-horizon as in the short trajectory setting.
Policy Evaluation
Policy Evaluation with IRASim. IRASim can simulate both successful and failed rollouts. Notably, it is able to simulate a bowl slipping from the gripper. The following video was rolled out with IRASim using a diffusion policy.
Simulated Model-Based Planning Experiment
We conduct experiments on the Push-T benchmark to demonstrate that IRASim can serve as a world model for model-based planning, enhancing the performance of vanilla manipulation policies. Specifically, we adapt a simple ranking algorithm for planning: (1) sample K trajectories from the policy, (2) simulate each trajectory using IRASim, and (3) select the one with the highest predicted value for execution.
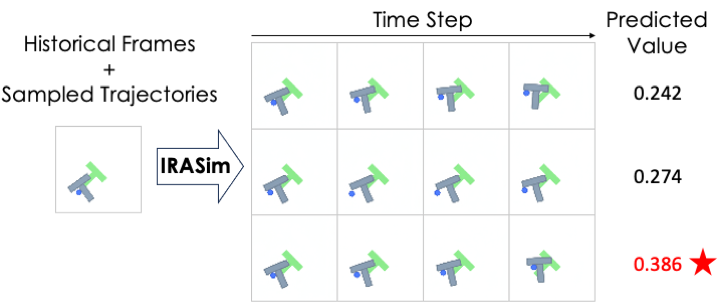
Figure 3. IRASim simulates the visual outcomes of candidate trajectories sampled from the policy and predicts the value of the final frame using a reward model. By selecting and executing the trajectory with the highest predicted value, we improve policy performance by leveraging additional test-time computation.
Real-World Model-Based Planning Experiment
We further evaluate IRASim in a real-world manipulation setting, showing that it can effectively plan trajectories by predicting the outcomes of candidate executions. The experiment validates IRASim’s utility in guiding real-robot decision-making.
Video results: The video below presents the visual outcomes predicted by IRASim (top) and the actual outcomes of real-world execution (bottom). Our comparison includes IRASim (ResNet), IRASim (MSE), and a random policy. Each policy selects different trajectories for execution. Both successful and failed outcomes are shown across three tasks: (1) closing a drawer, (2) placing a mandarin on a green plate, and (3) placing a mandarin on a red plate.
Top videos in each row are real rollouts; bottom videos are predicted by IRASim.
Flexible Action Controllability
In this section, we perform qualitative experiments in which we ''control'' the virtual robot in two datasets, Language-Table and RT-1, using trajectories collected with two distinct input sources: a keyboard and a VR controller. Notably, the trajectories collected through these input sources exhibit distributions that deviate from those in the original dataset. For Language-Table with a 2D translation action space, we use the arrow keys on the keyboard to input action trajectories. For RT-1 with a 3D action space, we use a VR controller to collect action trajectories as input. Specifically, we prompt IRASim with an image from each dataset and a trajectory collected with the keyboard or VR controller. IRASim is able to follow trajectories collected with different input sources and simulate robot-object interaction in a realistic and reasonable way. More importantly, it is able to robustly handle multimodality in generation.